







How to use the Snapdragon™ Neural Processing Engine (NPE) SDK with the Open-Q™ 820
What if your embedded system was able to determine when somebody was walking up to it, turning on the screen without user input? What if you were able to ask your embedded device to turn off using nothing but your voice? What if it knew what objects were around it with nothing but a camera? These are all problems that neural networks have been shown to help solve.
At its very core, a neural network is a computing system inspired by human brains. They are unique in the sense that they have the property to learn to do tasks by looking at pre-solved examples, and can extrapolate from those examples to produce reasonable output for future unknown inputs [1]. They are typically structured as a number of layers that feed into each other, with each layer performing some kind of learned transformation on the previous.
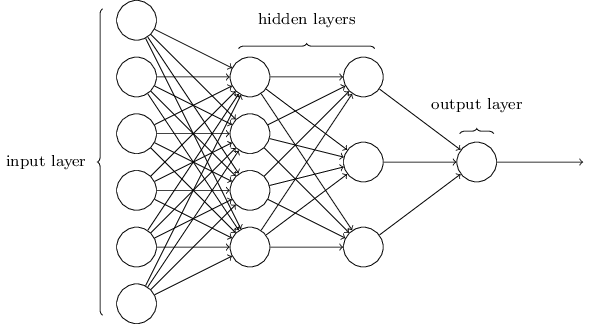
Figure 1 – Sample Structure of a Neural Network [4]
Neural networks, as it turns out, are highly suited to parallel computation making them excellent targets for running on a GPU or DSP. Notably, many of Intrinsyc’s offerings have included Qualcomm Hexagon DSP and/or Qualcomm Adreno GPU as part of the included Snapdragon chipset.
For instance, the Open-Q™ 820 SOM contains the Snapdragon 820 which includes the Qualcomm Adreno 530 GPU and the Qualcomm Hexagon 680 DSP. While it has been possible to achieve large speed ups using the Qualcomm Hexagon DSP SDK and the Qualcomm Adreno GPU SDK to handle the computation intensive portions of software, it is now possible to achieve large performance accelerations without any DSP or GPU specific knowledge or programming thanks to the Snapdragon Neural Processing Engine (NPE) SDK.
According to Qualcomm’s download page, “the Qualcomm Snapdragon Neural Processing Engine (NPE) SDK is designed to help developers run one or more neural network models trained in Caffe/Caffe2 or TensorFlow on Snapdragon mobile platforms, whether that is the CPU, GPU or DSP” [2]. By taking an existing and pre-trained neural network in Caffe/Caffe2 or Tensorflow format and using the tools included with the Snapdragon Neural Processing Engine, it is possible to get feed-forward inference running on the GPU or DSP on Snapdragon chipsets.
As an example, let us take a look at performing object detection on the Open-Q™ 820 development kit using a neural network. Object detection is the “finding and classifying a variable number of objects on an image” [3]. It is an area that has received a lot of recent improvements from researchers developing better ways to utilize neural networks and deep learning tools to detect objects in an image. For more information on the history of object detection, there is a fantastic infographic available here.
For this example, the tiny-yolo network has been slightly altered, trained, and converted using the Snapdragon NPE SDK to be able to run on an Open-Q™ 820 development kit. Running inside a host Android application, the neural network is trained to detect a multitude of different objects, including a cube, miniature rocket ship, and a permanent marker. As seen below, the demo is able to detect, in real time, multiple different objects.
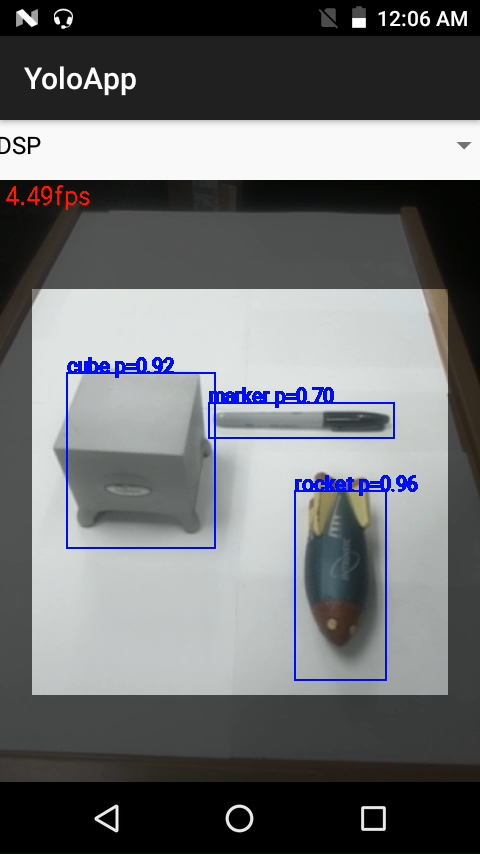
Figure 2 – The Example Application Running on the Qualcomm Hexagon 680 DSP
Most importantly, by utilizing the Snapdragon Neural Processing Engine it is possible to run the network on the GPU and DSP without any additional work. Running the sample application’s neural network on the Qualcomm Hexagon 680 DSP, for instance, results in the network running 145% faster while being 107% more power efficient. This is with the camera image pre-processing and post-processing still occurring on the CPU.
The application works by retrieving a YUV image stream of the camera from the Android system. As fast as the application is able to, it takes the next image available from the camera and converts it to the raw RGB format accepted by the YOLO network. This raw data is sent to the Snapdragon NPE Runtime, which then handles running the pre-converted neural network on the CPU, GPU, or DSP based on the requested runtime targets. When the network finishes executing, the raw output of the final layer of the network is returned to the Android application, which then parses and displays the results on the screen.
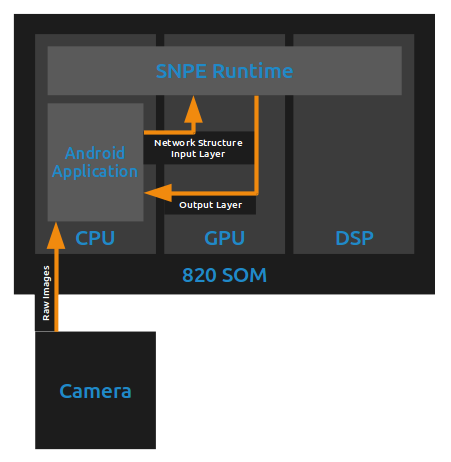
Figure 3 – Data Flow of the Sample Application
Since the computationally intensive portion of the application – the feedforward inference of the neural network – is running on the Snapdragon NPE Runtime, it is a simple matter of changing configuration values to change where the majority of the computation occurs. By changing the runtime target of the Snapdragon NPE, it is possible to see how the framerate of the application changes as the computations are moved from the CPU to the GPU or DSP.
Running the entire Android application on the CPU yields approximately 1.77 fps. By offloading the neural network portion of the computation onto the GPU and DSP increases performance up to 5.39 fps or 4.33 fps respectively. This is a 204%/145% increase in processing speed when running on these highly parallel chips.
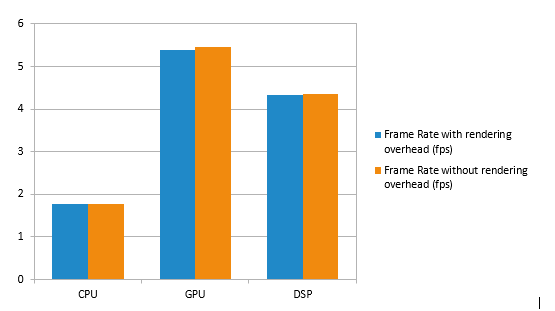
Figure 4 – Framerate of Running the Example Application on the CPU, GPU, and DSP
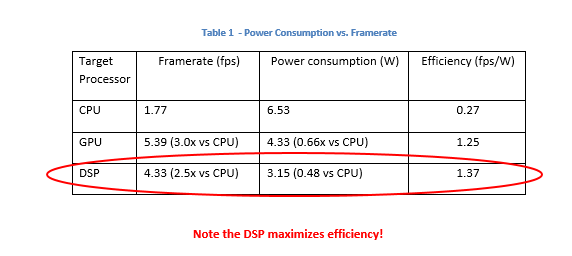
It is also possible to measure the power usage of the program while running the neural network. Using a digital multi-meter in conjunction with the application, it can be observed that running the application entirely on the CPU requires approximately 6.53W of power. When the feed-forward operation is offloaded onto the GPU or DSP using the Snapdragon NPE, however, the average power usage drops to 4.33W and 3.15W respectively. This is equivalent to showing that running the neural network on the GPU causes the overall application to be 50.5% more efficient in power usage over the CPU, and 107.4% when run with the DSP.
Figure 5 – Power Consumption of the Sample Application Running with the Neural Network Operation Performed on the CPU, GPU, and DSP
Note that these power measurements are without restricting the speed of processing, so the DSP and GPU are using less power to achieve a higher processing speed compared to the CPU. See the table below for a summary of efficiency in fps/W for each case.
What these results show, however, is not only that the Open-Q™ 820 SOM is able to run object detection in real-time, but rather that it has the ability to run arbitrary deep learning problems in an embedded context in a way that is not only highly power-efficient, but also quite fast. By using the Snapdragon NPE, developers are not required to learn how to program on the GPU or the DSP, but can instead just directly deploy their pre-trained neural network onto their embedded device and immediately start receiving some of the performance gains of running on the GPU and DSP.
References
| [1] | D. Shiffman, “The Nature of Code – Chapter 10. Neural Networks,” [Online]. Available: http://natureofcode.com/book/chapter-10-neural-networks/. |
| [2] | Qualcomm Technologies, Inc., “Snapdragon Neural Processing Engine,” [Online]. Available: https://developer.qualcomm.com/software/snapdragon-neural-processing-engine. [Accessed 21 Dec 2017]. |
| [3] | J. Rey, “Object detection: an overview in the age of Deep Learning,” 2017 30 Aug. [Online]. Available: https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/. [Accessed 21 Dec 2017]. |
| [4] | M. A. Nielsen, “Neural Networks and Deep Learning,” Determination Press, 2015. [Online]. Available: http://neuralnetworksanddeeplearning.com/chap1.html. [Accessed 21 Dec 2017]. |
Author: Brandon Mabey, Intrinsyc Software Engineer, Co-op Student
Related Posts

January 28, 2026 Technical Articles
LMOS 6.8: Practical Updates for Enterprise Out-of-Band Management
Lantronix LMOS 6.8 is now available for the LM-Series Console Servers and Lantronix Control Center. This relea…

December 11, 2023 Technical Articles
Reducing Unscheduled Downtime: Fighting for Each Additional ‘Nine’ of Network Availability
Reconciling network management strategies with business needs involves balancing uptime service level requirem…